JVM笔记
注意
本文大部分内容摘抄自《JVM核心技术32讲》 (opens new window),感谢作者。
# JDK、JRE、JVM 之间的关系
JDK
JDK(Java Development Kit) 是用于开发 Java 应用程序的软件开发工具集合,包括了 Java 运行时的环境(JRE)、解释器(Java)、编译器(javac)、Java 归档(jar)、文档生成器(Javadoc)等工具。简单的说我们要开发 Java 程序,就需要安装某个版本的 JDK 工具包。
JRE
JRE(Java Runtime Enviroment )提供 Java 应用程序执行时所需的环境,由 Java 虚拟机(JVM)、核心类、支持文件等组成。简单的说,我们要是想在某个机器上运行 Java 程序,可以安装 JDK,也可以只安装 JRE,后者体积比较小。
JVM
Java Virtual Machine(Java 虚拟机)有三层含义,分别是:
- JVM规范要求;
- 满足 JVM 规范要求的一种具体实现(一种计算机程序);
- 一个 JVM 运行实例,在命令提示符下编写 Java 命令以运行 Java 类时,都会创建一个 JVM 实例,我们下面如果只记到 JVM 则指的是这个含义;如果我们带上了某种 JVM 的名称,比如说是 Zing JVM,则表示上面第二种含义。
JDK 与 JRE、JVM 之间的关系
就范围来说,JDK > JRE > JVM:
- JDK = JRE + 开发工具
- JRE = JVM + 类库
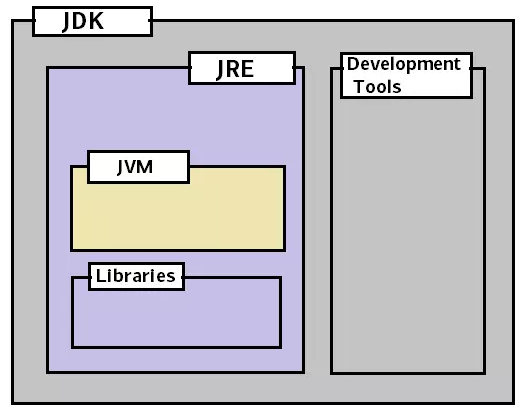
三者在开发运行 Java 程序时的交互关系:
简单的说,就是通过 JDK 开发的程序,编译以后,可以打包分发给其他装有 JRE 的机器上去运行。而运行的程序,则是通过 Java 命令启动的一个 JVM 实例,代码逻辑的执行都运行在这个 JVM 实例上。
Java 程序的开发运行过程为:
我们利用 JDK (调用 Java API)开发 Java 程序,编译成字节码或者打包程序。然后可以用 JRE 则启动一个 JVM 实例,加载、验证、执行 Java 字节码以及依赖库,运行 Java 程序。而 JVM 将程序和依赖库的 Java 字节码解析并变成本地代码执行,产生结果。
# 常见的编程语言类型
从底向上划分为最基本的三大类:机器语言、汇编语言、高级语言。
# 高级语言分类
如果按照有没有虚拟机来划分,高级编程语言可分为两类:
- 有虚拟机:Java,Lua,Ruby,部分 JavaScript 的实现等等
- 无虚拟机:C,C++,C#,Golang,以及大部分常见的编程语言
如果按照变量是不是有确定的类型,还是类型可以随意变化来划分,高级编程语言可以分为:
- 静态类型:Java,C,C++ 等等
- 动态类型:所有脚本类型的语言
如果按照是编译执行,还是解释执行,可以分为:
- 编译执行:C,C++,Golang,Rust,C#,Java,Scala,Clojure,Kotlin,Swift 等等
- 解释执行:JavaScript 的部分实现和 NodeJS,Python,Perl,Ruby 等等
这里面,C# 和 Java 都是编译后生成了一种中间类型的目标代码(类似汇编),但不是汇编或机器码,在C#中称为 微软中间语言(MSIL),在 Java 里叫做 Java 字节码(Java bytecode)。
此外,我们还可以按照语言特点分类:
- 面向过程:C,Basic,Pascal,Fortran 等等;
- 面向对象:C++,Java,Ruby,Smalltalk 等等;
- 函数式编程:LISP、Haskell、Erlang、OCaml、Clojure、F# 等等。
# 关于跨平台
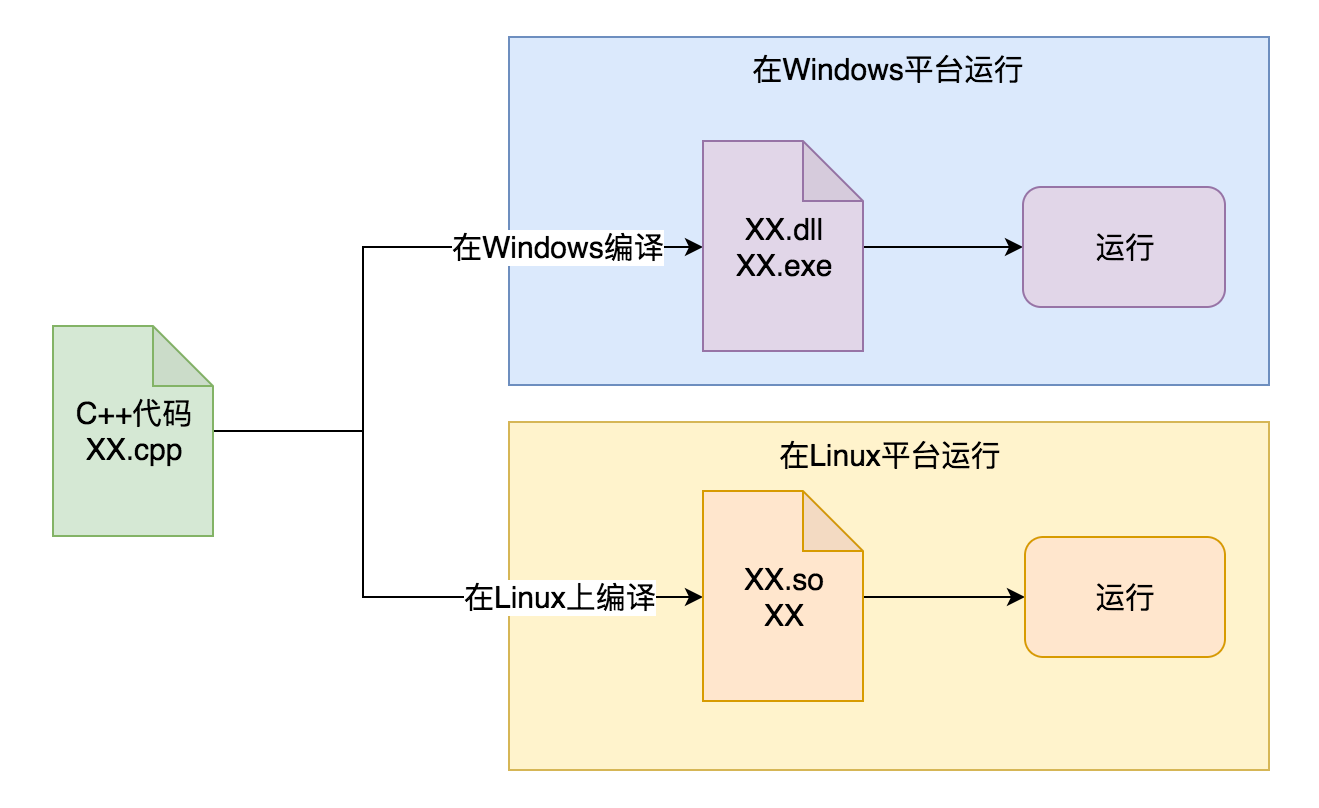
1、典型的源码跨平台(C++):
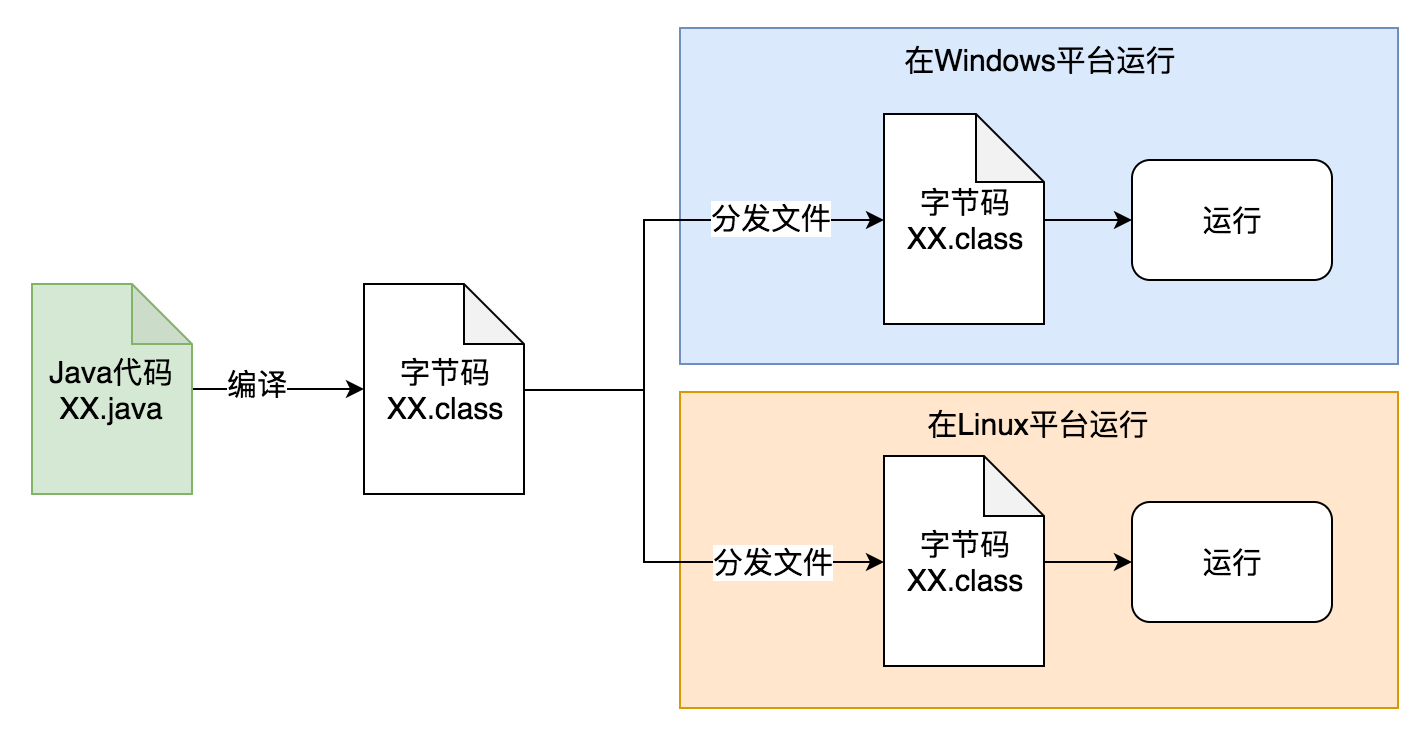
2、典型的二进制跨平台(Java 字节码):
C++ 里我们需要把一份源码,在不同平台上分别编译,生成这个平台相关的二进制可执行文件,然后才能在相应的平台上运行。 这样就需要在各个平台都有开发工具和编译器,而且在各个平台所依赖的开发库都需要是一致或兼容的。 这一点在过去的年代里非常痛苦,被戏称为 “依赖地狱”。
C++ 的口号是“一次编写,到处(不同平台)编译”,但实际情况上是一编译就报错,变成了 “一次编写,到处调试,到处找依赖、改配置”。 大家可以想象,你编译一份代码,发现缺了几十个依赖,到处找还找不到,或者找到了又跟本地已有的版本不兼容,这是一件怎样令人绝望的事情。
而 Java 语言通过虚拟机技术率先解决了这个难题。 源码只需要编译一次,然后把编译后的 class 文件或 jar 包,部署到不同平台,就可以直接通过安装在这些系统中的 JVM 上面执行。 同时可以把依赖库(jar 文件)一起复制到目标机器,慢慢地又有了可以在各个平台都直接使用的 Maven 中央库(类似于 linux 里的 yum 或 apt-get 源,macos 里的 homebrew,现代的各种编程语言一般都有了这种包依赖管理机制:python 的 pip,dotnet 的 nuget,NodeJS 的 npm,golang 的 dep,rust 的 cargo 等等)。这样就实现了让同一个应用程序在不同的平台上直接运行的能力。
# 关于运行时(Runtime)与虚拟机(VM)
简单的说 JRE 就是 Java 的运行时,包括虚拟机和相关的库等资源。
可以说运行时提供了程序运行的基本环境,JVM 在启动时需要加载所有运行时的核心库等资源,然后再加载我们的应用程序字节码,才能让应用程序字节码运行在 JVM 这个容器里。
# 关于内存管理和垃圾回收(GC)
- C/C++ 完全相信而且惯着程序员,让大家自行管理内存,所以可以编写很自由的代码,但一个不小心就会造成内存泄漏等问题导致程序崩溃。
- Java/Golang 完全不相信程序员,但也惯着程序员。所有的内存生命周期都由 JVM 运行时统一管理。 在绝大部分场景下,你可以非常自由的写代码,而且不用关心内存到底是什么情况。 内存使用有问题的时候,我们可以通过 JVM 来信息相关的分析诊断和调整。 这也是本课程的目标。
- Rust 语言选择既不相信程序员,也不惯着程序员。 让你在写代码的时候,必须清楚明白的用 Rust 的规则管理好你的变量,好让机器能明白高效地分析和管理内存。 但是这样会导致代码不利于人的理解,写代码很不自由,学习成本也很高。
# 字节码技术
Java 中的字节码,英文名为 bytecode, 是 Java 代码编译后的中间代码格式。JVM 需要读取并解析字节码才能执行相应的任务。
Java bytecode 由单字节(byte)的指令组成,理论上最多支持 256 个操作码(opcode)。实际上 Java 只使用了 200 左右的操作码, 还有一些操作码则保留给调试操作。
# 类加载器
我们可以用 Java 命令指定主启动类,或者是 Jar 包,通过约定好的机制,JVM 就会自动去加载对应的字节码(可能是 class 文件,也可能是 Jar 包)。
按照 Java 语言规范和 Java 虚拟机规范的定义, 我们用 “类加载(Class Loading)” 来表示: 将 class/interface 名称映射为 Class 对象的一整个过程。 这个过程还可以划分为更具体的阶段: 加载,链接和初始化(loading, linking and initializing)。
# 类的生命周期和加载过程
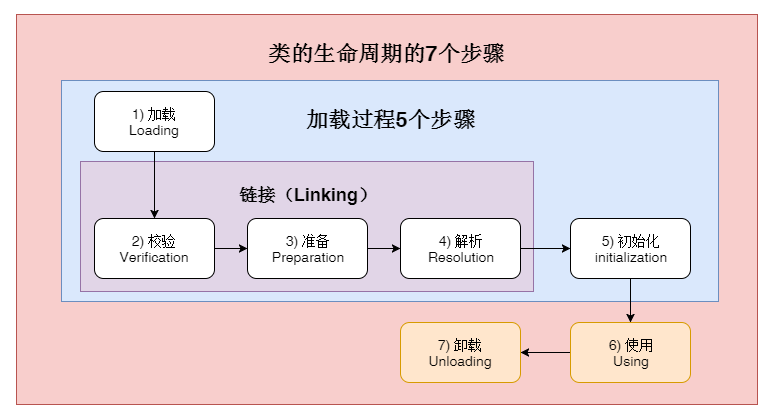
一个类在 JVM 里的生命周期有 7 个阶段,分别是加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)、卸载(Unloading)。
其中前五个部分(加载,验证,准备,解析,初始化)统称为类加载。
JVM 规范明确规定, 必须在类的首次“主动使用”时才能执行类初始化。
初始化的过程包括执行:
- 类构造器方法
- static 静态变量赋值语句
- static 静态代码块
# 类加载时机
JVM 规范枚举了下述多种触发情况:
- 当虚拟机启动时,初始化用户指定的主类,就是启动执行的 main 方法所在的类;
- 当遇到用以新建目标类实例的 new 指令时,初始化 new 指令的目标类,就是 new 一个类的时候要初始化;
- 当遇到调用静态方法的指令时,初始化该静态方法所在的类;
- 当遇到访问静态字段的指令时,初始化该静态字段所在的类;
- 子类的初始化会触发父类的初始化;
- 如果一个接口定义了 default 方法,那么直接实现或者间接实现该接口的类的初始化,会触发该接口的初始化;
- 使用反射 API 对某个类进行反射调用时,初始化这个类,其实跟前面一样,反射调用要么是已经有实例了,要么是静态方法,都需要初始化;
- 当初次调用 MethodHandle 实例时,初始化该 MethodHandle 指向的方法所在的类。
同时以下几种情况不会执行类初始化:
- 通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化。
- 定义对象数组,不会触发该类的初始化。
- 常量在编译期间会存入调用类的常量池中,本质上并没有直接引用定义常量的类,不会触发定义常量所在的类。
- 通过类名获取 Class 对象,不会触发类的初始化,Hello.class 不会让 Hello 类初始化。
- 通过 Class.forName 加载指定类时,如果指定参数 initialize 为 false 时,也不会触发类初始化,其实这个参数是告诉虚拟机,是否要对类进行初始化。Class.forName(“jvm.Hello”)默认会加载 Hello 类。
- 通过 ClassLoader 默认的 loadClass 方法,也不会触发初始化动作(加载了,但是不初始化)。
示例: 诸如 Class.forName(), classLoader.loadClass() 等 Java API, 反射API, 以及 JNI_FindClass 都可以启动类加载。 JVM 本身也会进行类加载。 比如在 JVM 启动时加载核心类,java.lang.Object, java.lang.Thread 等等。
# 内存模型
JVM 是一个完整的计算机模型,所以自然就需要有对应的内存模型,这个模型被称为 “Java 内存模型”,对应的英文是“Java Memory Model”,简称 JMM。
# JVM 内存结构
JVM 内部使用的 Java 内存模型, 在逻辑上将内存划分为 线程栈(thread stacks)和堆内存 (heap)两个部分。 如下图所示:
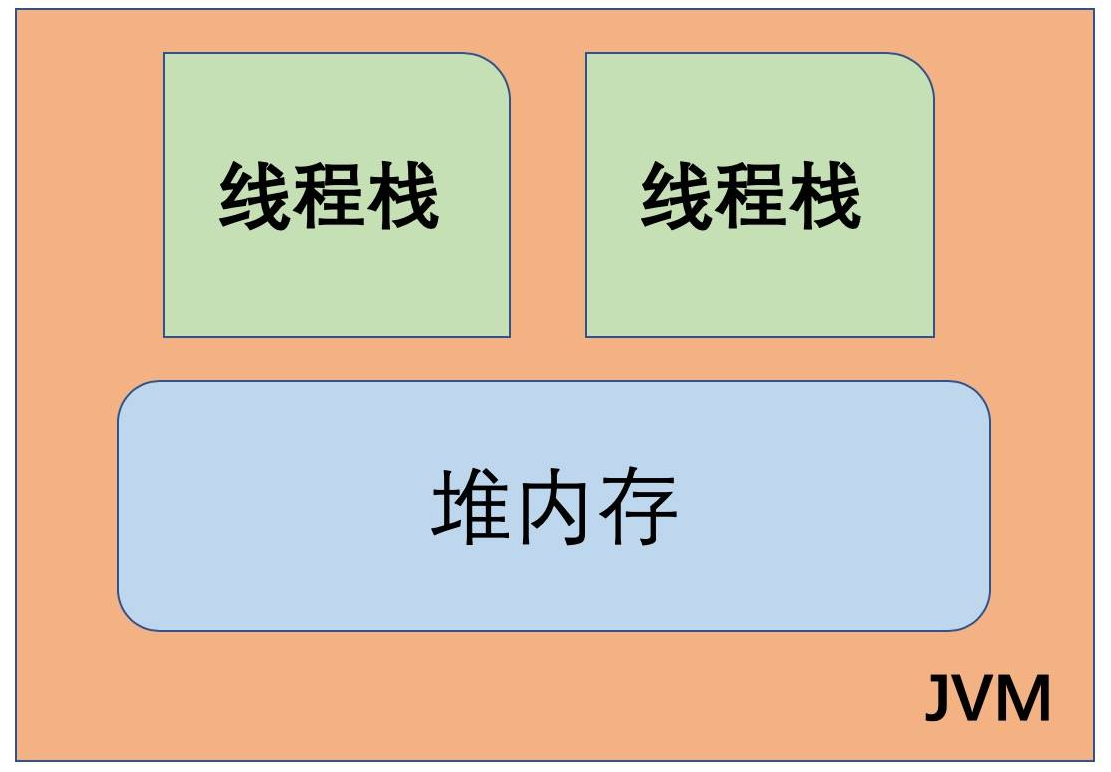
JVM 中,每个正在运行的线程,都有自己的线程栈。 线程栈包含了当前正在执行的方法链/调用链上的所有方法的状态信息。
所以线程栈又被称为“方法栈”或“调用栈”(call stack)。线程在执行代码时,调用栈中的信息会一直在变化。
线程栈里面保存了调用链上正在执行的所有方法中的局部变量。
- 每个线程都只能访问自己的线程栈。
- 每个线程都不能访问(看不见)其他线程的局部变量。
即使两个线程正在执行完全相同的代码,但每个线程都会在自己的线程栈内创建对应代码中声明的局部变量。 所以每个线程都有一份自己的局部变量副本。
- 所有原生类型的局部变量都存储在线程栈中,因此对其他线程是不可见的。
- 线程可以将一个原生变量值的副本传给另一个线程,但不能共享原生局部变量本身。
- 堆内存中包含了 Java 代码中创建的所有对象,不管是哪个线程创建的。 其中也涵盖了包装类型(例如
Byte,Integer,Long等)。 - 不管是创建一个对象并将其赋值给局部变量, 还是赋值给另一个对象的成员变量, 创建的对象都会被保存到堆内存中。
总结:原始数据类型和对象引用地址在栈上;对象、对象成员与类定义、静态变量在堆上。
堆内存又称为“共享堆”,堆中的所有对象,可以被所有线程访问, 只要他们能拿到对象的引用地址。
- 如果一个线程可以访问某个对象时,也就可以访问该对象的成员变量。
- 如果两个线程同时调用某个对象的同一方法,则它们都可以访问到这个对象的成员变量,但每个线程的局部变量副本是独立的。
总结:虽然各个线程自己使用的局部变量都在自己的栈上,但是大家可以共享堆上的对象,特别地各个不同线程访问同一个对象实例的基础类型的成员变量,会给每个线程一个变量的副本。
# 栈内存的结构
每启动一个线程,JVM 就会在栈空间栈分配对应的线程栈, 比如 1MB 的空间(-Xss1m)。
线程执行过程中,一般会有多个方法组成调用栈(Stack Trace), 比如 A 调用 B,B 调用 C……每执行到一个方法,就会创建对应的栈帧(Frame)。
栈帧是一个逻辑上的概念,具体的大小在一个方法编写完成后基本上就能确定。
比如 返回值 需要有一个空间存放,每个局部变量都需要对应的地址空间,此外还有给指令使用的 操作数栈,以及 class 指针(标识这个栈帧对应的是哪个类的方法, 指向非堆里面的 Class 对象)。
# 堆内存的结构
堆内存是所有线程共用的内存空间,理论上大家都可以访问里面的内容。
但 JVM 的具体实现一般会有各种优化。比如将逻辑上的 Java 堆,划分为堆(Heap)和非堆(Non-Heap)两个部分.。这种划分的依据在于,我们编写的 Java 代码,基本上只能使用 Heap 这部分空间,发生内存分配和回收的主要区域也在这部分,所以有一种说法,这里的 Heap 也叫 GC 管理的堆(GC Heap)。
GC 理论中有一个重要的思想,叫做分代。 经过研究发现,程序中分配的对象,要么用过就扔,要么就能存活很久很久。因此,JVM 将 Heap 内存分为年轻代(Young generation)和老年代(Old generation, 也叫 Tenured)两部分。
Non-Heap 本质上还是 Heap,只是一般不归 GC 管理。
# JMM 简介
目前的 JMM 规范对应的是 “JSR-133. Java Memory Model and Thread Specification (opens new window)” ,这个规范的部分内容润色之后就成为了《Java语言规范》的 $17.4. Memory Model章节 (opens new window)。
JMM 定义了一些术语和规定:
- 能被多个线程共享使用的内存称为“
共享内存”或“堆内存”。 - 所有的对象(包括内部的实例成员变量),static 变量,以及数组,都必须存放到堆内存中。
- 局部变量,方法的形参/入参,异常处理语句的入参不允许在线程之间共享,所以不受内存模型的影响。
- 多个线程同时对一个变量访问时【读取/写入】,这时候只要有某个线程执行的是写操作,那么这种现象就称之为“冲突”。
- 可以被其他线程影响或感知的操作,称为线程间的交互行为, 可分为: 读取、写入、同步操作、外部操作等等。 其中同步操作包括:对 volatile 变量的读写,对管程(monitor)的锁定与解锁,线程的起始操作与结尾操作,线程启动和结束等等。 外部操作则是指对线程执行环境之外的操作,比如停止其他线程等等。
JMM 规范的是线程间的交互操作,而不管线程内部对局部变量进行的操作。
# JVM 启动参数
JVM 作为一个通用的虚拟机,我们可以通过启动 Java 命令时指定不同的 JVM 参数,让 JVM 调整自己的运行状态和行为,内存管理和垃圾回收的 GC 算法,添加和处理调试和诊断信息等等。
直接通过命令行启动 Java 程序的格式为:
java [options] classname [args]
java [options] -jar filename [args]
2
3
其中:
[options]部分称为 "JVM 选项",对应 IDE 中的 VM options, 可用jps -v查看。[args]部分是指 "传给main函数的参数", 对应 IDE 中的 Program arguments, 可用jps -m查看。
Java 和 JDK 内置的工具,指定参数时都是一个 -,不管是长参数还是短参数。
JVM 的启动参数, 从形式上可以简单分为:
- 以
-开头为标准参数,所有的 JVM 都要实现这些参数,并且向后兼容。 - 以
-X开头为非标准参数, 基本都是传给 JVM 的,默认 JVM 实现这些参数的功能,但是并不保证所有 JVM 实现都满足,且不保证向后兼容。 - 以
-XX:开头为非稳定参数, 专门用于控制 JVM 的行为,跟具体的 JVM 实现有关,随时可能会在下个版本取消。 -XX:+-Flags形式,+-是对布尔值进行开关。-XX:key=value形式, 指定某个选项的值。
# Agent 相关的选项
Agent 是 JVM 中的一项黑科技, 可以通过无侵入方式来做很多事情,比如注入 AOP 代码,执行统计等等,权限非常大。
设置 agent 的语法如下:
-agentlib:libname[=options]启用native方式的agent, 参考LD_LIBRARY_PATH路径。-agentpath:pathname[=options]启用native方式的agent。-javaagent:jarpath[=options]启用外部的agent库, 比如pinpoint.jar等等。-Xnoagent则是禁用所有 agent。
# JVM 运行模式
JVM 有两种运行模式:
-server:设置 jvm 使 server 模式,特点是启动速度比较慢,但运行时性能和内存管理效率很高,适用于生产环境。在具有 64 位能力的 jdk 环境下将默认启用该模式,而忽略 -client 参数。-client:JDK1.7 之前在 32 位的 x86 机器上的默认值是-client选项。设置 jvm 使用 client 模式,特点是启动速度比较快,但运行时性能和内存管理效率不高,通常用于客户端应用程序或者PC应用开发和调试。
# 设置堆内存
JVM 的内存设置是最重要的参数设置,也是 GC 分析和调优的重点。
特别注意
JVM 总内存=堆+栈+非堆+堆外内存
相关的参数:
-Xmx, 指定最大堆内存。 如-Xmx4g. 这只是限制了 Heap 部分的最大值为 4g。这个内存不包括栈内存,也不包括堆外使用的内存。-Xms, 指定堆内存空间的初始大小。 如-Xms4g。 而且指定的内存大小,并不是操作系统实际分配的初始值,而是 GC 先规划好,用到才分配。 专用服务器上需要保持-Xms和-Xmx一致,否则应用刚启动可能就有好几个 FullGC。当两者配置不一致时,堆内存扩容可能会导致性能抖动。-Xmn, 等价于-XX:NewSize,使用 G1 垃圾收集器 不应该 设置该选项,在其他的某些业务场景下可以设置。官方建议设置为-Xmx的1/2 ~ 1/4。-XX:MaxPermSize=size, 这是 JDK1.7 之前使用的。Java8 默认允许的 Meta 空间无限大,此参数无效。-XX:MaxMetaspaceSize=size, Java8 默认不限制 Meta 空间, 一般不允许设置该选项。XX:MaxDirectMemorySize=size,系统可以使用的最大堆外内存,这个参数跟-Dsun.nio.MaxDirectMemorySize效果相同。-Xss, 设置每个线程栈的字节数。 例如-Xss1m指定线程栈为 1MB,与-XX:ThreadStackSize=1m等价
这里要特别说一下堆外内存,也就是说不在堆上的内存,我们可以通过jconsole,jvisualvm 等工具查看。
# 配置多少 xmx 合适
推荐配置系统或容器里可用内存的 70-80% 最好。比如说系统有 8G 物理内存,系统自己可能会用掉一点,大概还有 7.5G 可以用,那么建议配置
-Xmx6g 说明:xmx : 7.5G*0.8 = 6G,如果知道系统里有明确使用堆外内存的地方,还需要进一步降低这个值。
# xmx 和 xms 是不是要配置成一致的
一般情况下,我们的服务器是专用的,就是一个机器(也可能是云主机或 docker 容器)只部署一个 Java 应用,这样的时候建议配置成一样的,好处是不会再动态去分配,如果内存不足很容易被发现。
# GC 日志相关的参数
JVM 启动参数为我们提供了一些用于控制 GC 日志输出的选项。
-verbose:gc:和其他 GC 参数组合使用, 在 GC 日志中输出详细的GC信息。 包括每次 GC 前后各个内存池的大小,堆内存的大小,提升到老年代的大小,以及消耗的时间。此参数支持在运行过程中动态开关。比如使用 jcmd, jinfo, 以及使用 JMX 技术的其他客户端。-XX:+PrintGCDetails和-XX:+PrintGCTimeStamps:打印 GC 细节与发生时间。请关注我们后续的 GC 课程章节。-Xloggc:file:与-verbose:gc功能类似,只是将每次 GC 事件的相关情况记录到一个文件中,文件的位置最好在本地,以避免网络的潜在问题。若与 verbose:gc 命令同时出现在命令行中,则以 -Xloggc 为准。
示例:
export JAVA_OPTS="-Xms28g -Xmx28g -Xss1m \
-verbosegc -XX:+UseG1GC -XX:MaxGCPauseMillis=200 \
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/"
2
3
# JDK 内置命令行工具
JDK 自带的工具和程序可以分为 2 大类型:
- 开发工具
- 诊断分析工具
# JDK 内置的开发工具
下面列举常用的部分:
| 工具 | 简介 |
|---|---|
| java | Java 应用的启动程序 |
| javac | JDK 内置的编译工具 |
| javap | 反编译 class 文件的工具 |
| javadoc | 根据 Java 代码和标准注释,自动生成相关的 API 说明文档 |
| javah | JNI 开发时,根据 Java 代码生成需要的 .h 文件。 |
| extcheck | 检查某个 jar 文件和运行时扩展 jar 有没有版本冲突,很少使用 |
| jdb | Java Debugger 可以调试本地和远端程序,属于 JPDA 中的一个 Demo 实现,供其他调试器参考。开发时很少使用 |
| jdeps | 探测 class 或 jar 包需要的依赖 |
| jar | 打包工具,可以将文件和目录打包成为 .jar 文件;.jar 文件本质上就是 zip 文件,只是后缀不同。使用时按顺序对应好选项和参数即可。 |
| keytool | 安全证书和密钥的管理工具(支持生成、导入、导出等操作) |
| jarsigner | jar 文件签名和验证工具 |
| policytool | 实际上这是一款图形界面工具,管理本机的 Java 安全策略 |
# 命令行诊断和分析工具
JDK 内置了各种命令行工具。
# jps
JPS,用于展示 Java 进程信息(列表)。
jps -v
# output
15883 Jps -Dapplication.home=/usr/local/jdk1.8.0_74 -Xms8m
6446 Jstatd -Dapplication.home=/usr/local/jdk1.8.0_74 -Xms8m
-Djava.security.policy=/etc/java/jstatd.all.policy
32383 Bootstrap -Xmx4096m -XX:+UseG1GC -verbose:gc
-XX:+PrintGCDateStamps -XX:+PrintGCDetails
-Xloggc:/xxx-tomcat/logs/gc.log
-Dcatalina.base=/xxx-tomcat -Dcatalina.home=/data/tomcat
2
3
4
5
6
7
8
9
10
输出的内容,其中最重要的信息是前面的进程 ID(PID)。知道 JVM 进程的 PID 之后,就可以使用其他工具来进行诊断了。
# jstat
jstat 用来监控 JVM 内置的各种统计信息,主要是内存和 GC 相关的信息。在没有其他监控工具的情况下, jstat 可以简单查看各个内存池和 GC 的信息,可用于判别是否是 GC 问题或者内存溢出。
# jmap
面试最常问的就是 jmap 工具了。jmap 主要用来 Dump 堆内存。当然也支持输出统计信息。
官方推荐使用 JDK 8 自带的 jcmd 工具来取代 jmap,但是 jmap 深入人心,jcmd 可能暂时取代不了。
# 看堆内存统计信息
jmap -heap 4524
# Dump 堆内存
jmap -dump:format=b,file=3826.hprof 3826
2
3
4
5
导出完成后,dump 文件大约和堆内存一样大。可以想办法压缩并传输。分析 hprof 文件可以使用 jhat 或者 mat (opens new window) 工具。
# jcmd
诊断工具:jcmd 是 JDK 8 推出的一款本地诊断工具,只支持连接本机上同一个用户空间下的 JVM 进程。
# Dump 堆内存
jcmd 11155 help GC.heap_dump
2
jcmd 坑的地方在于,必须指定绝对路径,否则导出的 hprof 文件就以 JVM 所在的目录计算(因为是发命令交给 JVM 执行的)。
# jstack
命令行工具、诊断工具:jstack 工具可以打印出 Java 线程的调用栈信息(Stack Trace)。一般用来查看存在哪些线程,诊断是否存在死锁等。这时候就看出来给线程(池)命名的必要性了(开发不规范,整个项目都是坑),具体可参考阿里巴巴的 Java 开发规范。
选项说明:
-F:强制执行 Thread Dump,可在 Java 进程卡死(hung 住)时使用,此选项可能需要系统权限。-m:混合模式(mixed mode),将 Java 帧和 native 帧一起输出,此选项可能需要系统权限。-l:长列表模式,将线程相关的 locks 信息一起输出,比如持有的锁,等待的锁。
常用的选项是 -l,示例用法:
jstack 4524
jstack -l 4524
2
死锁的原因一般是锁定多个资源的顺序出了问题(交叉依赖), 网上示例代码很多,比如搜索“Java 死锁 示例”。
在 Linux 和 macOS 上,jstack pid 的效果跟 kill -3 pid 相同。
# JDK 内置图形界面工具
GUI 图形界面工具,主要是 3 款:JConsole、JVisualVM、JMC。其实这三个产品可以说是 3 代不同的 JVM 分析工具。
这三个工具都支持我们分析本地 JVM 进程,或者通过 JMX 等方式连接到远程 JVM 进程。当然,图形界面工具的版本号和目标 JVM 不能差别太大,否则可能会报错。
# JConsole
JConsole,顾名思义,就是“Java 控制台”,在这里,我们可以从多个维度和时间范围去监控一个 Java 进程的内外部指标。进而通过这些指标数据来分析判断 JVM 的状态,为我们的调优提供依据。
在 Windows 或 macOS 的运行窗口或命令行输入 jconsole,然后回车就可以打开。
# JVisualVM
在命令行或者运行窗口直接输入jvisualvm即可启动。
JVisualVM 最强大的地方在于插件。最常用的插件是 VisualGC 和 MBeans。
# JMC
JMC 和 JVisualVM 功能类似,因为 JMC 的前身是 JRMC,JRMC 是 BEA 公司的 JRockit JDK 自带的分析工具,被 Oracle 收购以后,整合成了 JMC 工具。Oracle 试图用 JMC 来取代 JVisualVM,在商业环境使用 JFR 需要付费获取授权。
在命令行输入jmc即可启动。
# Java 平台调试体系
Java 平台调试体系(Java Platform Debugger Architecture,JPDA),由三个相对独立的层次共同组成。这三个层次由低到高分别是 Java 虚拟机工具接口(JVMTI)、Java 调试连接协议(JDWP)以及 Java 调试接口(JDI)。详细介绍请参考或搜索:JPDA 体系概览 (opens new window)。
# 服务端 JVM 配置
本篇主要讲解如何在 JVM 中启用 JDWP,以供远程调试。假设主启动类是 com.xxx.Test。
java -Xdebug -Xrunjdwp:transport=dt_socket,address=8788,server=y,suspend=n com.xxx.Test
-Xdebug 这个选项什么用都没有,官方说是为了历史兼容性,避免报错才没有删除。
参数配置里的 suspend=y 会让 Java 进程启动时先挂起,等到有调试器连接上以后继续执行程序。
而如果改成 suspend=n 的话,则此 Java 进程会直接执行,但是我们可以随时通过调试器连上进程。
就是说,比如说我们启动一个 Web 服务器进程,当这个值是 y 的时候,服务器的 JVM 初始化以后不会启动 Web 服务器,会一直等到我们用 IDEA 或 Eclipse、JDB 等工具连上这个 Java 进程后,再继续启动 Web 服务器。而如果是 n 的话,则会不管有没有调试器连接,都会正常运行。
如果细心观察的话,会发现 IDEA 中 Debug 模式启动的程序,自动设置了类似的启动选项。
# JDB
启用了 JDWP 之后,可以使用各种客户端来进行调试/远程调试。比如 JDB 调试本地 JVM:
jdb -attach 'debug'
jdb -attach 8888
2
当 JDB 初始化并连接到 Test 之后,就可以进行 Java 代码级(Java-level)的调试。
但是 JDB 调试非常麻烦,我们一般还是在开发工具 IDE(IDEA、Eclipse)里调试代码。
JDB常用的命令
- 设置断点:
stop at 类名:行号
- 清除断点:
clear at 类名:行号
- 显示局部变量:
localx
- 显示变量 a 的值:
print a
- 显示当前线程堆栈:
wherei
- 代码执行到下一行:
next
- 代码继续执行,直到遇到下一个断点:
cont
# IDEA 中使用远程调试
在Run/Debug Configurations里添加Remote,设置host的debug端口号,点击Apply。
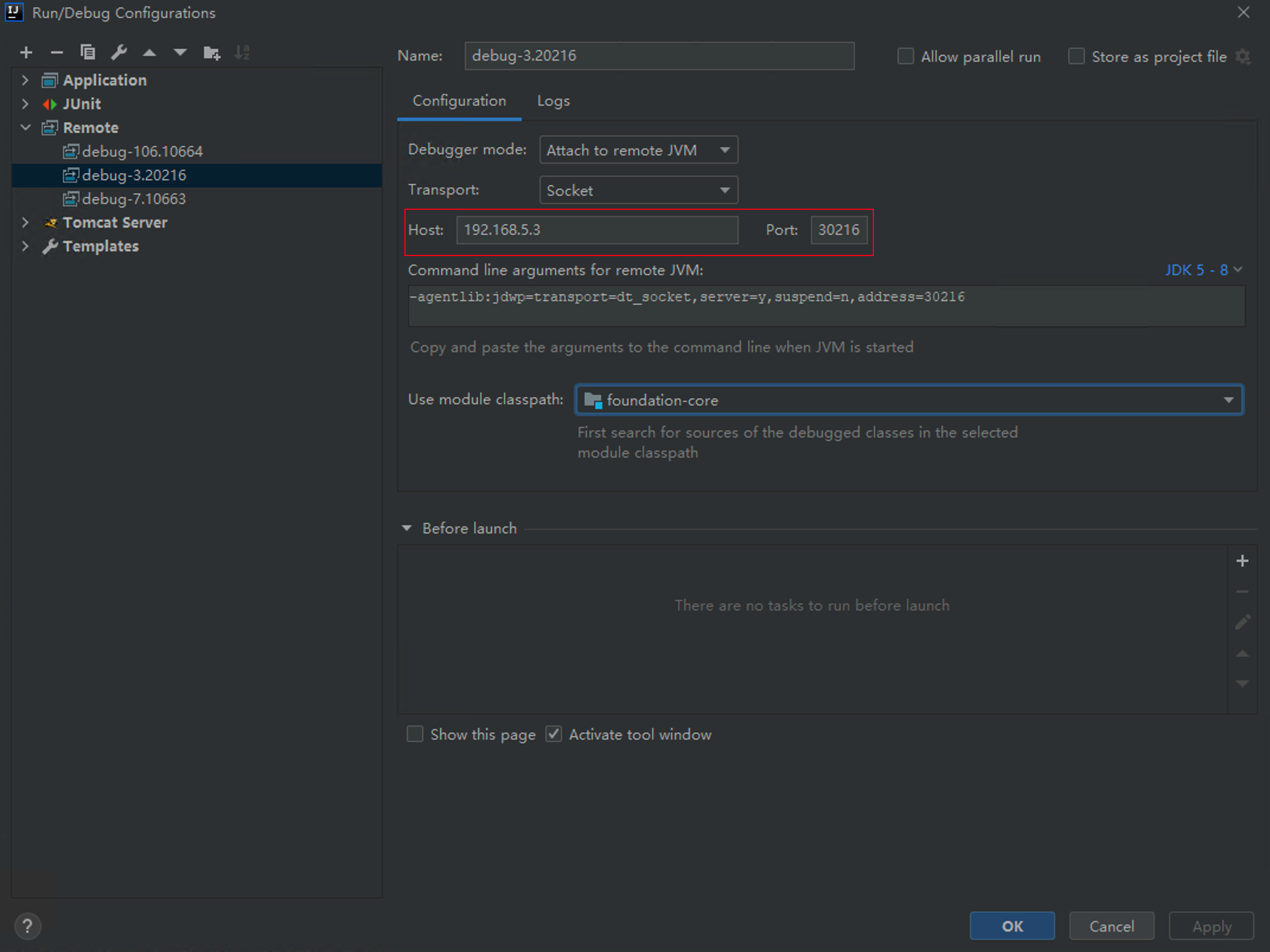
点击 Debug 的那个按钮即可启动远程调试,连上之后就和调试本地程序一样了。当然,记得加断点或者条件断点。
特别注意
远程调试时,需要保证服务端 JVM 中运行的代码和本地完全一致,否则可能会有莫名其妙的问题。
细心的同学可能已经发现,IDEA 给出了远程 JVM 的启动参数,建议使用 agentlib 的方式:
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=30216
JVM 为什么可以让不同的开发工具和调试器都连接上进行调试呢?因为它提供了一套公开的调试信息的交互协议,各家厂商就可以根据这个协议去实现自己的调试图形工具,进而方便 Java 开发人员的使用。
# JDWP 协议规范
JDWP 全称是 Java Debug Wire Protocol,中文翻译为“Java 调试连接协议”,是用于规范调试器(Debugger)与目标 JVM 之间通信的协议。
JDWP 支持两种调试场景:
- 同一台计算机上的其他进程
- 远程计算机上
与许多协议规范的不同之处在于,JDWP 只规定了具体的格式和布局,而不管你用什么协议来传输数据。
# JMX 与相关工具
Java 平台提供了全面的 JVM 监控和管理措施。
Java SE 5.0 版本引入了 JMX 技术(Java Management Extensions,Java 管理扩展),是用于监控和管理 JVM 资源(包括应用程序、设备、服务和 JVM)的一组标准 API。
最常见的 JMX 客户端是 JConsole 和 JVisualVM(可以安装各种插件,十分强大)。两个工具都是标准 JDK 的一部分,而且很容易使用. 如果使用的是 JDK 7u40 及更高版本,还可以使用另一个工具:Java Mission Control(JMC,大致翻译为 Java 控制中心)。