Python 多线程
参考:
- Global Interpreter Lock (opens new window):全局解释器锁
- threading (opens new window):Python 内置多线程模块
- queue (opens new window):A multi-producer, multi-consumer queue
- queue — 线程安全的 FIFO 队列 (opens new window)
- threading — 管理单个进程里的并行操作 (opens new window)
- 列表与队列—谈谈线程安全 (opens new window)
- 为什么Python多线程无法利用多核 (opens new window)
- Python 线程池原理及实现 (opens new window)
- Python 线程池及其原理和使用 (opens new window)
- ThreadPoolExecutor 判断所有任务已结束 (opens new window)
# threading 模块
使用线程的两种方式:
- 创建
threading.Thread的对象执行某个函数 - 创建
threading.Thread的子类,重写run方法
例子:
import threading
def task(task_id, task_name):
"""
多线程要执行的任务
:param task_id:
:param task_name:
:return:
"""
print(f"task(id: {task_id}, name: {task_name}) done!")
if __name__ == '__main__':
for i in range(5):
# 以args元组的形式传参
t = threading.Thread(target=task, args=(i, f"t{i}"))
# 以kwargs字典的形式传参
# t = threading.Thread(target=task, kwargs={"task_id": i, "task_name": f"t{i}"})
t.start()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这里顺便记录一下我自己之前一直不理解的地方,创建线程的时候如何给要执行的函数传参呢(多个参数)?
其实看一下Thread源码就很清楚了,如图:
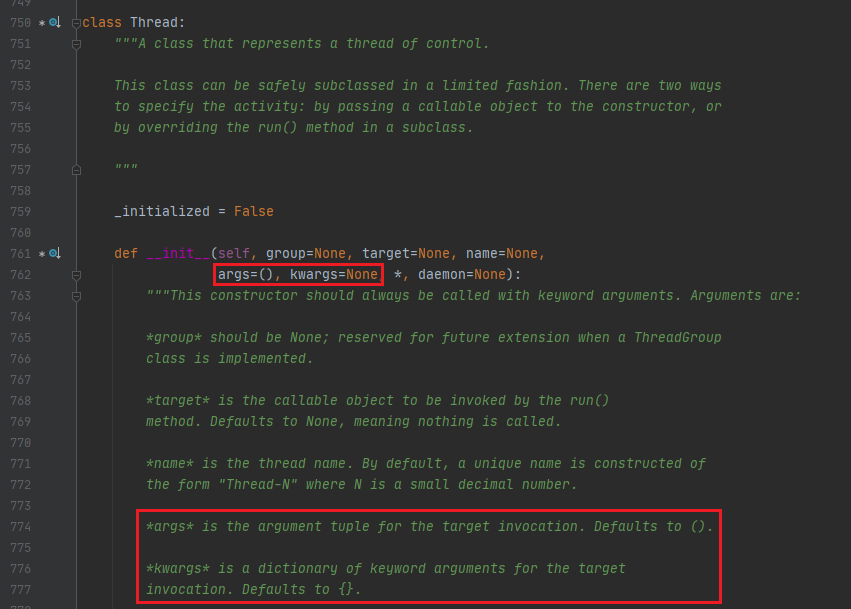
Thread的init方法提供了两种形式的参数,args默认值是一个空元组,kwargs默认值是None但是希望传的是字典。
再看一下run()方法是如何把参数传给我们要执行的target方法的:
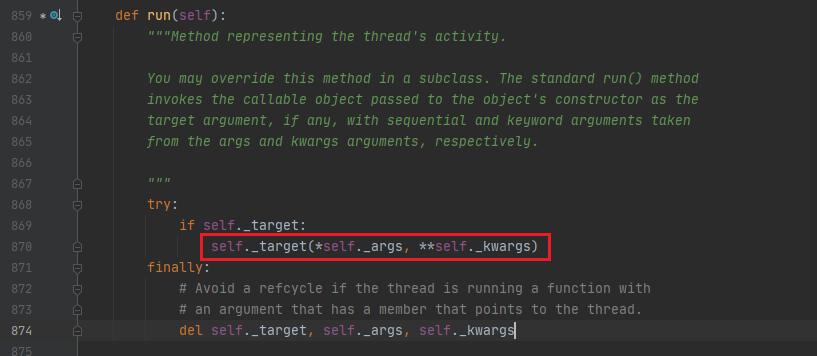
这就很清楚了,一个星号解包元组(或列表等),两个星号解包字典,所以不管是以元组的形式写到args里的参数,还是以字典形式写到kwargs里的参数,都会被解包后传到target方法。
# 多线程同步
不可避免的要考虑线程同步,这是一个例子:使用count进行全局任务计数,修改count值时需要保证线程同步,避免冲突。
import threading
import time
import random
total = 100
count = 0
lock = threading.Lock()
def task():
"""
执行一次任务,给count计数加1
:return:
"""
global total
global count
# 随机 sleep 0到1秒,模拟不同任务耗时不同
time.sleep(random.random())
# 这里线程同步锁
with lock:
count += 1
print(f"process: {count}/{total}")
if __name__ == '__main__':
thread_list = []
for i in range(100):
t = threading.Thread(target=task)
thread_list.append(t)
for t in thread_list:
t.start()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
你可以尝试把同步锁的代码注释掉,看看会发生什么。
加锁的地方也可以用下面这种写法:
# 获取锁
lock.acquire()
try:
# do something...
count += 1
print(f"process: {count}/{total}")
finally:
# 释放锁
lock.release()
2
3
4
5
6
7
8
9
10
# 守护线程
当程序中拥有多个线程时,主线程执行结束并不会影响子线程继续执行。换句话说,只有程序中所有线程全部执行完毕后,程序才算真正结束。
Python 还支持创建另一种线程,称为守护线程(或后台线程)。此类线程的特点是,当程序中主线程及所有非守护线程执行结束时,未执行完毕的守护线程也会随之消亡(进行死亡状态),程序将结束运行。
下面这个例子中,如果把t.daemon = True注释掉,则程序一直运行不退出。
import threading
import time
def task(task_id, task_name):
while True:
print(f"task(id: {task_id}, name: {task_name}) done!")
time.sleep(1)
if __name__ == '__main__':
for i in range(5):
t = threading.Thread(target=task, args=(i, f"t{i}"))
# 设为守护线程
t.daemon = True
t.start()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 使用queue实现线程池
Python官方文档的描述:queue 模块实现了多生产者、多消费者队列。这特别适用于消息必须安全地在多线程间交换的线程编程。
默认的queue.Queue是FIFO(先进先出)。
为什么要用线程池?
传统多线程方案会使用“即时创建, 即时销毁”的策略。虽然与创建进程相比,创建线程的开销已经很小,但是如果提交给线程的任务执行时间较短,而且执行很频繁,那么系统将处于不停的创建线程,销毁线程的状态。每次创建都需要经过启动、销毁和运行3个过程。这必然会增加系统相应的时间,降低了效率。
使用线程池:线程预先被创建并放入线程池中,处理完当前任务之后并不销毁而是被安排处理下一个任务,因此能够避免多次创建线程,从而节省线程创建和销毁的开销,能带来更好的性能和系统稳定性。
使用queue实现线程池的例子:
from queue import Queue
import threading
import time
# 创建队列, 用于存储任务
queue = Queue()
lock = threading.Lock()
def task():
while True:
if queue.empty():
# 如果任务队列已经为空,则休眠1秒
time.sleep(1)
else:
i = queue.get()
with lock:
# do something...
print(f"thread-{threading.current_thread().getName()}: execute task {i}")
queue.task_done()
if __name__ == '__main__':
# 创建包括3个线程的线程池
for i in range(3):
t = threading.Thread(target=task)
# 设为守护线程,当主线程退出并且只剩下守护线程时,则退出程序
t.daemon = True
t.start()
# 往任务队列添加10个任务
for i in range(10):
queue.put(i)
# 等待队列所有元素被取除
queue.join()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
输出:
thread-Thread-1: execute task 0
thread-Thread-1: execute task 1
thread-Thread-2: execute task 2
thread-Thread-1: execute task 3
thread-Thread-3: execute task 4
thread-Thread-3: execute task 7
thread-Thread-3: execute task 8
thread-Thread-3: execute task 9
thread-Thread-2: execute task 5
thread-Thread-1: execute task 6
2
3
4
5
6
7
8
9
10
可以看到自始至终只有3个执行任务的线程,10个任务中每个任务由哪个线程执行是不可预测的,哪个线程先取出任务就由哪个线程执行。
顺便记录一些注意点:
- 当队列为空时,如果直接使用
queue.get()则会阻塞(不会抛异常),直到队列中有元素。看文档的意思是,如果没用block是默认值True并且没用设置timeout,队列为空时就会无限等待😂。想要避免这种情况也很简单,把block设为False,则队列为空时会抛异常。
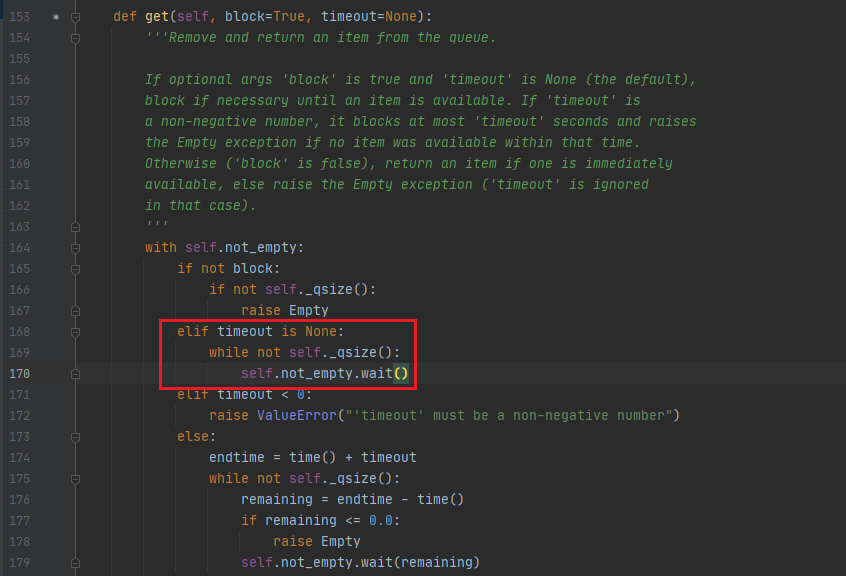
- python3中的print方法到底是不是线程安全的我也不清楚,实测来看,没有加锁时,多线程print有概率格式错乱(该换行的没换行),加了锁之后完全正常了,所以例子中的print还是加了锁。
# 使用ThreadPoolExecutor
线程池的基类是 concurrent.futures 模块中的 Executor,Executor 提供了两个子类,即 ThreadPoolExecutor 和 ProcessPoolExecutor,其中 ThreadPoolExecutor 用于创建线程池,而 ProcessPoolExecutor 用于创建进程池。
程序将 task 函数提交(submit)给线程池后,submit 方法会返回一个 Future 对象,Future 类主要用于获取线程任务函数的返回值。由于线程任务会在新线程中以异步方式执行,因此,线程执行的函数相当于一个“将来完成”的任务,所以 Python 使用 Future 来代表。
看这个例子:
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
import threading
import time
def task(task_id):
msg = f"{threading.current_thread().getName()} executed (task id: {task_id})"
time.sleep(1)
return msg
if __name__ == '__main__':
# 创建一个包含3个线程的线程池
pool = ThreadPoolExecutor(max_workers=3)
# Future对象列表
future_list = []
# 向线程池提交10个任务
for i in range(10):
future = pool.submit(task, i)
future_list.append(future)
# 等待所有任务结束(timeout 10秒)
wait(future_list, 10, ALL_COMPLETED)
# 获取所有任务返回值
for future in future_list:
print(future.result())
# 关闭线程池
pool.shutdown()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
输出:
ThreadPoolExecutor-0_0 executed (task id: 0)
ThreadPoolExecutor-0_1 executed (task id: 1)
ThreadPoolExecutor-0_2 executed (task id: 2)
ThreadPoolExecutor-0_2 executed (task id: 3)
ThreadPoolExecutor-0_0 executed (task id: 4)
ThreadPoolExecutor-0_1 executed (task id: 5)
ThreadPoolExecutor-0_2 executed (task id: 6)
ThreadPoolExecutor-0_1 executed (task id: 7)
ThreadPoolExecutor-0_0 executed (task id: 8)
ThreadPoolExecutor-0_2 executed (task id: 9)
2
3
4
5
6
7
8
9
10
与上面”使用queue和threading.Thread实现线程池“相比,ThreadPoolExecutor的优点:
- 可以获取任务的返回值
- 可以给提交不同的任务给线程池执行
- 不需要自己创建和维护任务队列,只需
submit后有空闲线程就立即执行