记第一次多线程爬虫
记录一下第一次用python做多线程爬虫遇到的问题以及解决方法。
# 简介
此前了解过一点python爬虫的库,会简单使用requests库,也写过一点静态页面的爬虫。一直想爬一下LOL的皮肤图片,这几天终于下定决心做了。
LOL官网英雄资料页面:https://lol.qq.com/data/info-heros.shtml
经过磕磕绊绊总算是完成了,在这个过程中学到了很多东西,也是第一次爬取动态数据和使用多线程。
# 结果
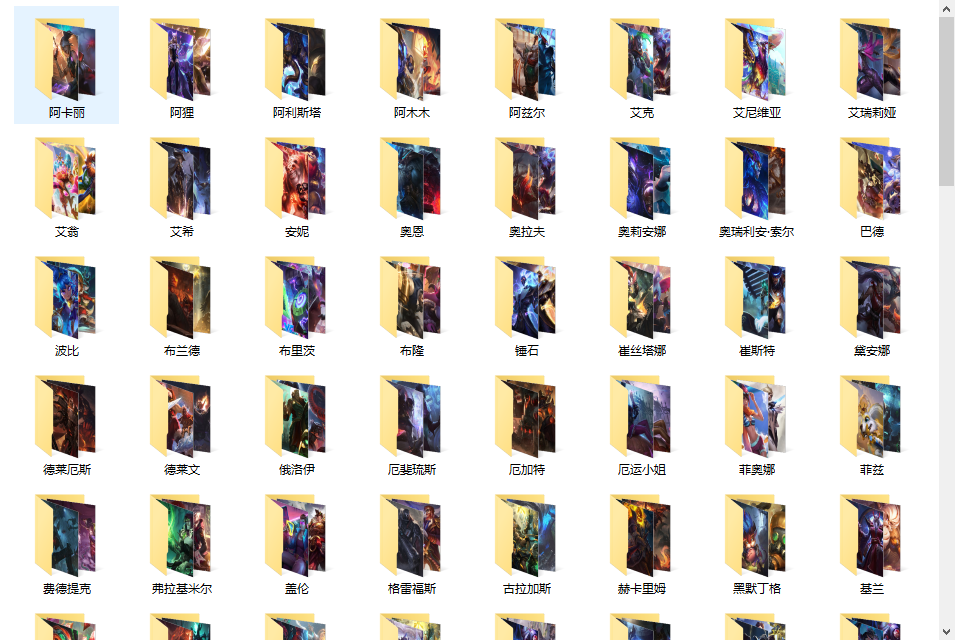
目前有148个英雄共1181个皮肤。 单线程用时226秒:

多线程用时30秒: (10个线程)

# 源码
# 1、单线程
import requests
import os
import json
import time
def spiders_lol():
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"
}
hero_list_url = "https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js"
hero_list_resp = requests.get(hero_list_url, headers=headers)
hero_list_resp.encoding = 'unicode_escape'
hero_list = json.loads(hero_list_resp.text)
dir_name = "LOL"
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# 保存一份hero_list.js到本地
with open(dir_name + "/hero_list.js", "w") as f:
f.write(str(hero_list))
print("已保存hero_list.json")
global hero_count
global skin_count
for hero in hero_list["hero"]:
print("正在下载第%d个英雄%s的皮肤:" % (hero_count, hero["title"]))
hero_dir = dir_name + "/" + hero["title"]
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
hero_info_url = "https://game.gtimg.cn/images/lol/act/img/js/hero/" + hero["heroId"] + ".js"
hero_info_resp = requests.get(hero_info_url, headers=headers)
# hero_info_resp.encoding = 'unicode_escape'
try:
hero_info = json.loads(hero_info_resp.text, strict=False)
except Exception as e:
print(e)
continue
# print(json.dumps(hero_info, ensure_ascii=False, indent=4))
for skin in hero_info["skins"]:
url = skin["mainImg"]
# 有的炫彩皮肤没有图片url,直接跳过
if url == '':
continue
r = requests.get(url, headers=headers)
# 有的图片名字包括/,把它去掉
skin_name = skin["name"].replace('/', '') + ".jpg"
with open(hero_dir + "/" + skin_name, "wb") as f:
f.write(r.content)
print("------%s" % skin_name)
skin_count += 1
print("%s的所有皮肤下载完成!" % hero["title"])
print("=======================================")
hero_count += 1
if __name__ == '__main__':
time_start=time.time()
hero_count = 1
skin_count = 0
spiders_lol()
time_end=time.time()
print("共下载了%d个英雄的%d个皮肤。" % (hero_count-1, skin_count))
print("用时 %.3f 秒" % float(time_end - time_start))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# 2、多线程
import requests
import os
import json
import time
from queue import Queue
from threading import Thread
import threading
def spiders_lol(in_q, out_q):
global headers
global dir_name
# 任务队列不为空则执行一个任务
while in_q.empty() is not True:
hero = in_q.get()
hero_dir = dir_name + "/" + hero["title"]
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
hero_info_url = "https://game.gtimg.cn/images/lol/act/img/js/hero/" + hero["heroId"] + ".js"
hero_info_resp = requests.get(hero_info_url, headers=headers)
# hero_info_resp.encoding = 'unicode_escape'
try:
hero_info = json.loads(hero_info_resp.text, strict=False)
except Exception as e:
print(e)
# print(json.dumps(hero_info, ensure_ascii=False, indent=4))
for skin in hero_info["skins"]:
url = skin["mainImg"]
# 有的炫彩皮肤没有图片url,直接跳过
if url == '':
continue
r = requests.get(url, headers=headers)
# 有的图片名字包括/,把它去掉
skin_name = skin["name"].replace('/', '') + ".jpg"
with open(hero_dir + "/" + skin_name, "wb") as f:
f.write(r.content)
print("------%s" % skin_name)
out_q.put("------%s" % skin_name)
# 该任务结束
in_q.task_done()
# 爬取hero_list,包含所有英雄的信息
def spiders_hero_list():
global headers
global dir_name
hero_list_url = "https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js"
hero_list_resp = requests.get(hero_list_url, headers=headers)
hero_list_resp.encoding = 'unicode_escape'
hero_list = json.loads(hero_list_resp.text)
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# 保存一份hero_list.js到本地
with open(dir_name + "/hero_list.js", "w") as f:
f.write(str(hero_list))
print("已保存hero_list.json")
return hero_list
if __name__ == '__main__':
time_start=time.time()
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"
}
dir_name = "LOL"
hero_list = spiders_hero_list()
# 创建两个队列,分别保存任务和结果
queue = Queue()
result_queue = Queue()
# 每个任务爬取一个英雄的皮肤
for hero in hero_list["hero"]:
queue.put(hero)
# 英雄个数
hero_count = queue.qsize()
# 创建10个线程来执行任务
for index in range(10):
thread = Thread(target=spiders_lol, args=(queue, result_queue))
# 随主线程退出而退出
thread.daemon = True
thread.start()
# 等待队列中任务全部处理完毕,与queue.task_done配合使用
queue.join()
# 皮肤数量
skin_count = result_queue.qsize()
time_end=time.time()
print("共下载了%d个英雄的%d个皮肤。" % (hero_count, skin_count))
print("用时 %.3f 秒" % float(time_end - time_start))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
# 遇到的问题
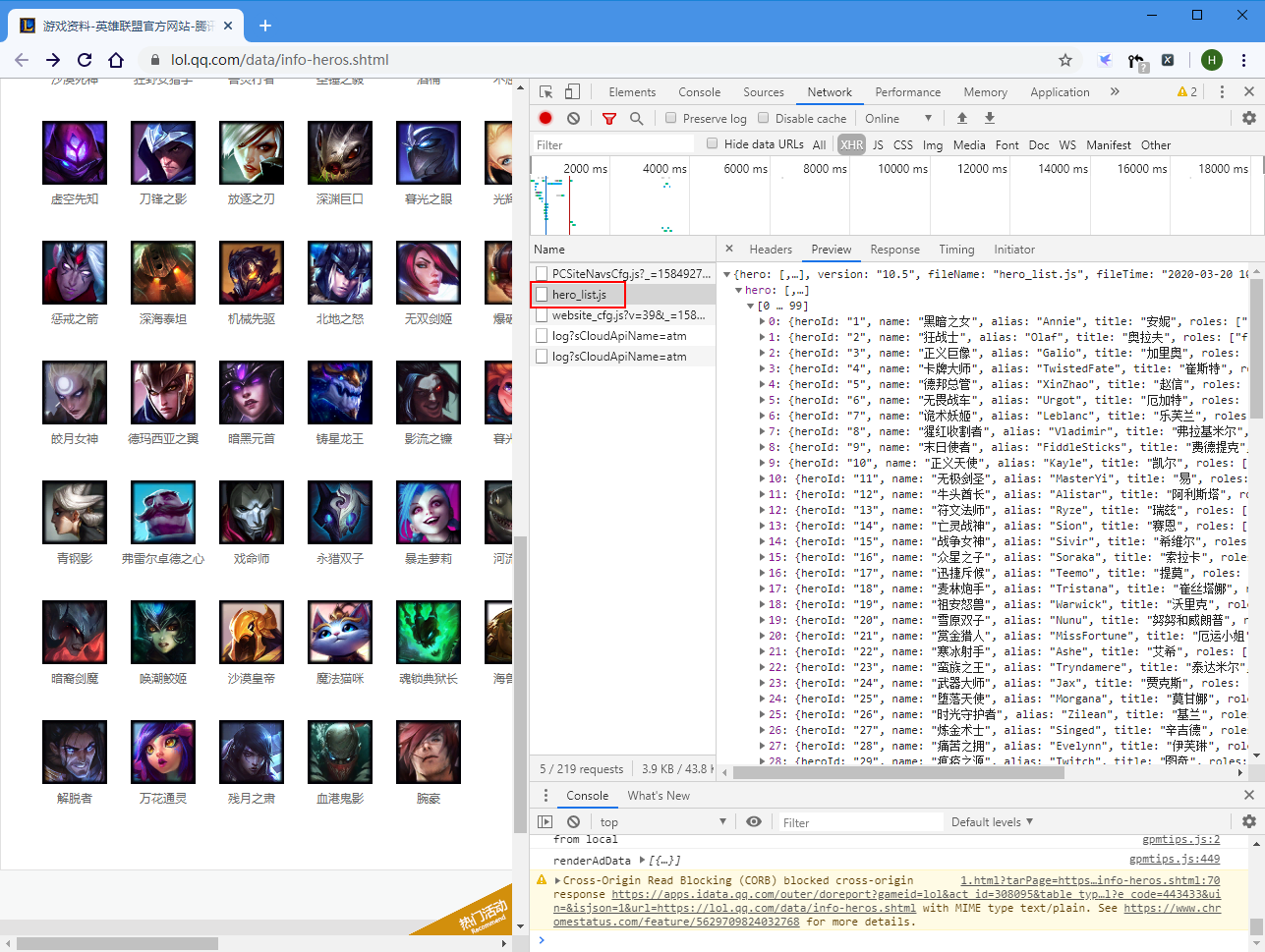
# 1、数据不在html源码中
LOL官网不是静态页面,而是动态数据。
要爬取皮肤的图片,就是要找到图片的url,然后get下来保存为图片。 查看官网源码并没有数据,只是一个壳子。

再往下翻,发现所有数据都是通过https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js 这个js文件加载的。

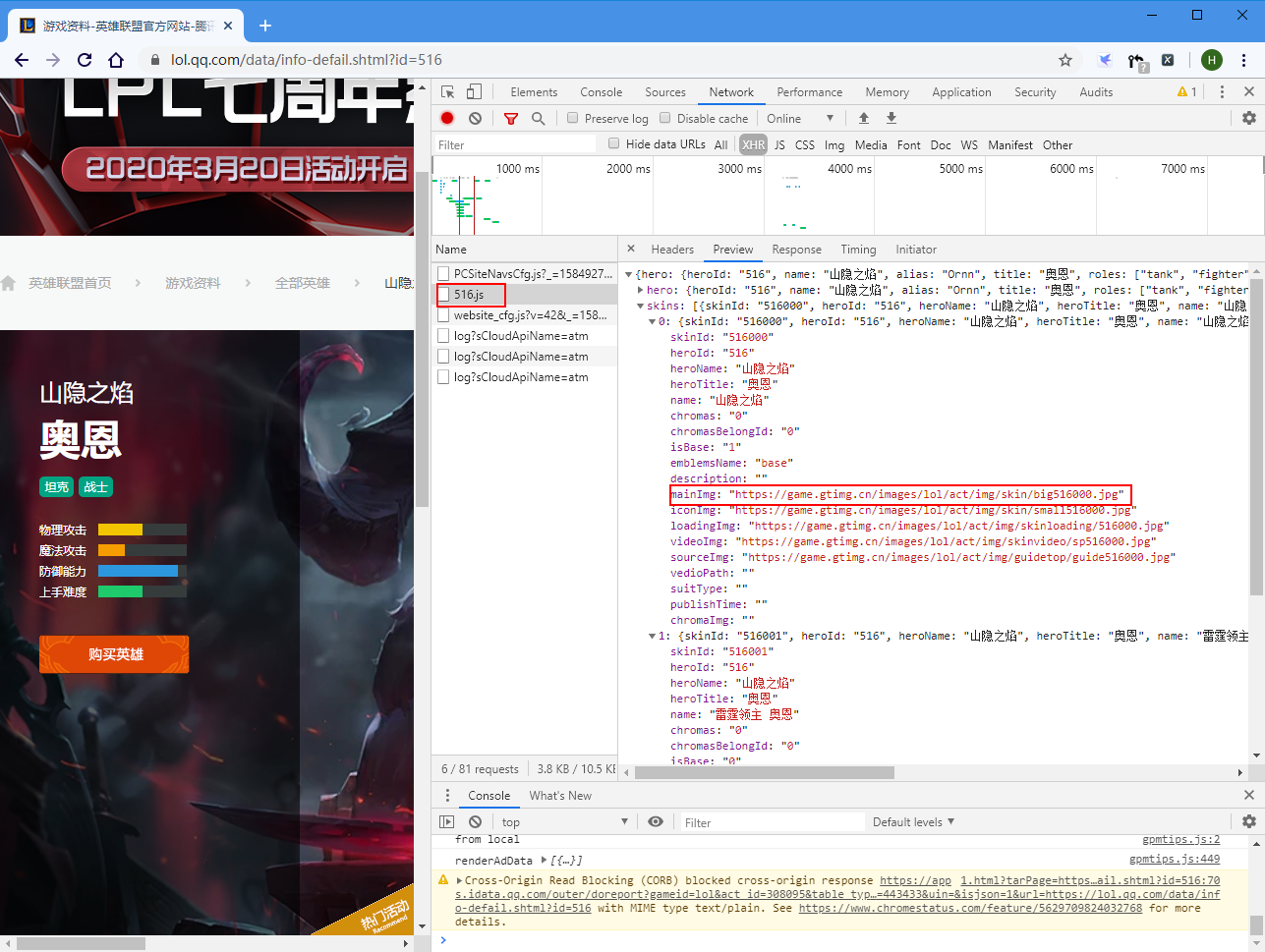
查看一下hero_list.js,果然包含所有的英雄信息。其中重要的是heroId,通过这个字段可以找到英雄详情页面。比如https://lol.qq.com/data/info-defail.shtml?id=516,“516”这个id就是heroId。这个数字并不是连续的,所以很重要。
在英雄详情页面又可以找到heroId.js,比如516.js。包含该英雄的所有皮肤的url。
# 2、requests爬取到的中文编码问题
这个问题我上一篇写了为什么会乱码:2020-03-19 为什么requests库有时中文会乱码
总结一下requests库中文乱码的解决的办法:
- 首先不要加任何东西,让requests自己选择解码。(我因为自己加了解码方式导致本来正常的解码出现了意想不到的错误,排查了很久。。。所以先信任requests的解码吧,有问题再修改。)
- 出现中文乱码的问题,自己修改编码方式。(从html里找到chartset) 比如:
response.encoding = 'gbk'
# 3、有的炫彩皮肤图片url为空

url为空是会报错的,所以加个判断,为空就跳过它。
# 4、有的皮肤名字包括斜杠/
比如这个“K/DA 伊芙琳”
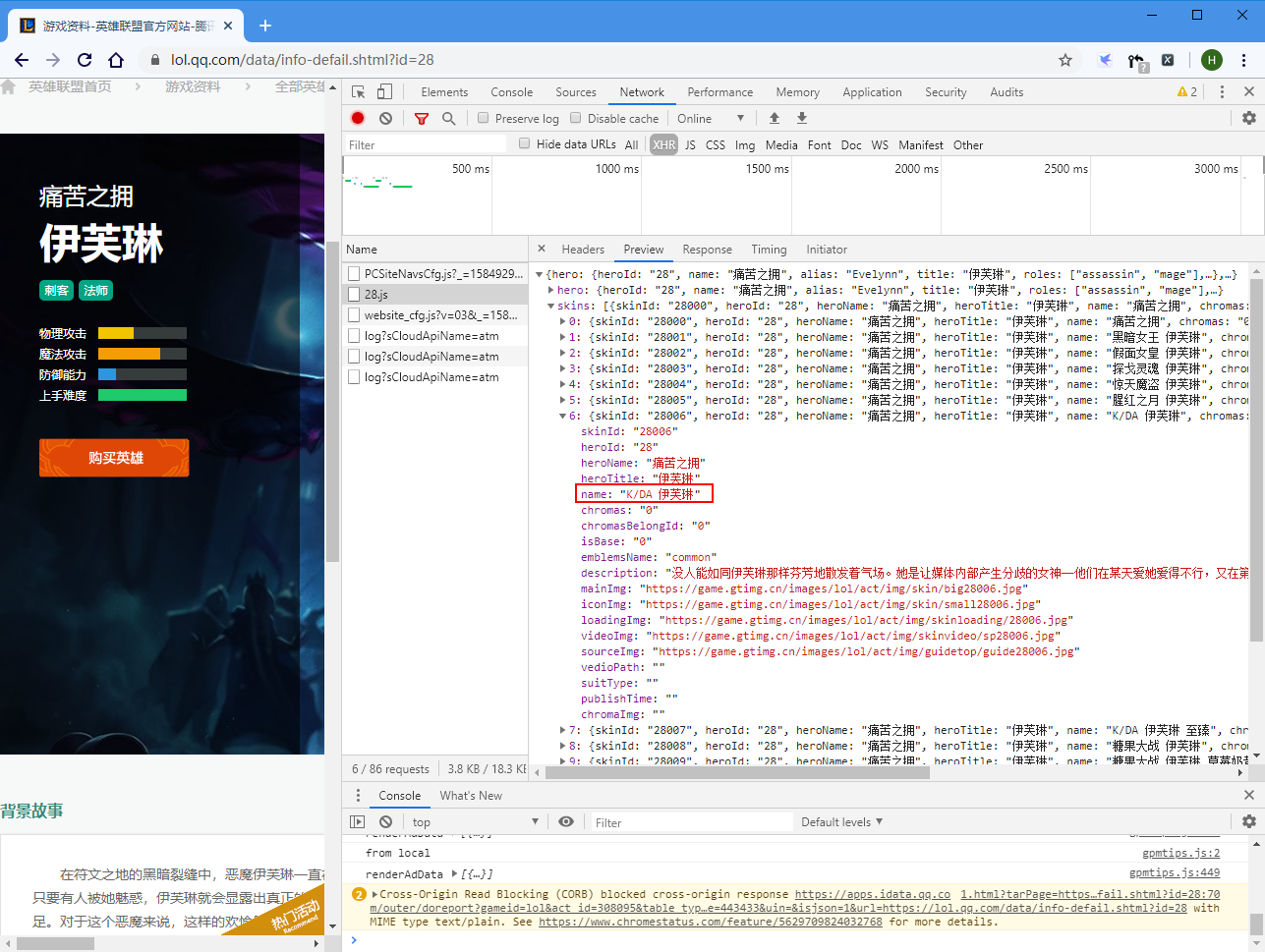
保存时斜杠会被认为是子目录,因为文件夹不存在而报错,我这里是直接把/去掉了。
# 5、第一次使用多线程
学习了这篇文章: https://blog.csdn.net/qq_40244755/article/details/90043484 只使用了最简单的方式,还得多学。
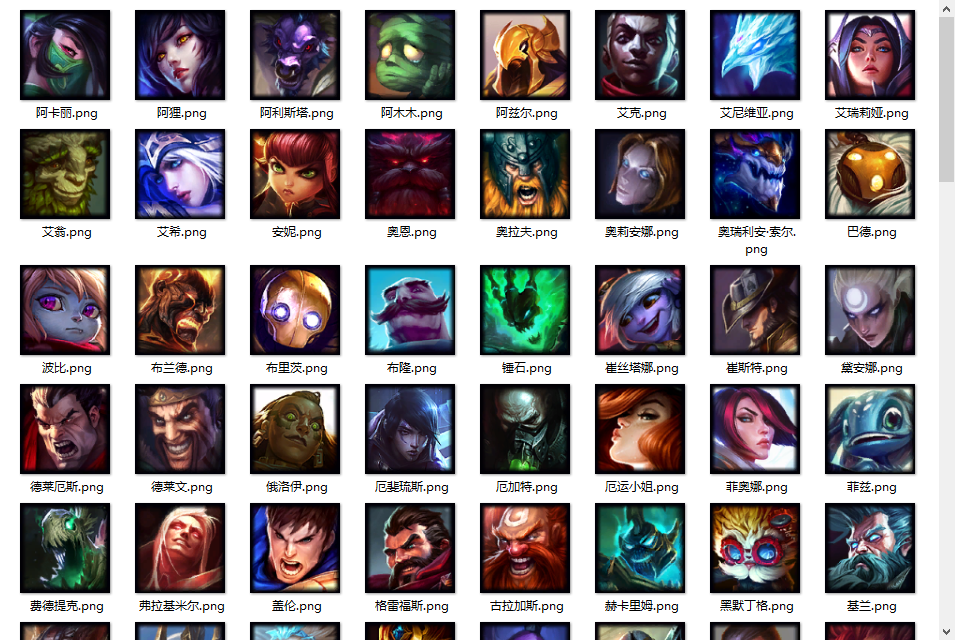
# 附:爬取所有英雄头像的代码
import requests
import os
import json
import time
# 爬取LOL英雄头像
def spiders_lol_head():
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"
}
hero_list_url = "https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js"
response = requests.get(hero_list_url, headers=headers)
response.encoding = 'unicode_escape'
hero_list = json.loads(response.text)
dir_name = "LOL英雄头像"
global count
if not os.path.exists(dir_name):
os.mkdir(dir_name)
for hero in hero_list["hero"]:
url = "https://game.gtimg.cn/images/lol/act/img/champion/" + hero["alias"] + ".png"
r = requests.get(url, headers=headers)
file_name = hero["title"] + ".png"
with open(dir_name + "/" + file_name, "wb") as f:
f.write(r.content)
print("------%s" % file_name)
count += 1
if __name__ == '__main__':
time_start = time.time()
count = 0
spiders_lol_head()
time_end = time.time()
print("用时 %.3f 秒" % float(time_end - time_start))
print("共下载了 %d 个图片。" % count)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37