为什么requests库有时中文会乱码
post date: 2020-03-19
requests是python常用的HTTP库。 它支持自动响应内容的编码,但有时中文也会乱码。
# 中文乱码肯定是编码的问题
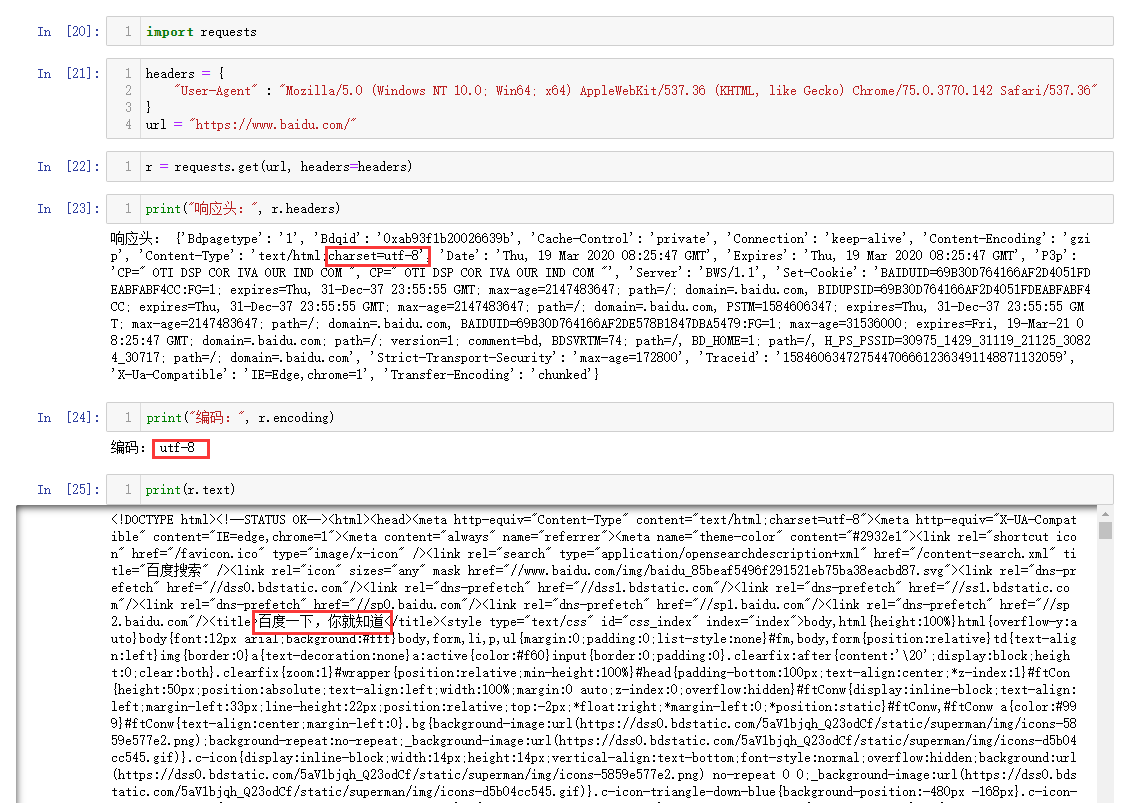
一般情况下requests库会根据响应头里的charset来选择相应的解码方式。 如抓取百度首页:
但是当响应头没有charset时,requests就会采用默认的“ISO-8859-1”编码,这种编码是不支持中文的,所以中文肯定会乱码。 例如抓取LOL首页:

该响应头没有说明charset,所以requests采用默认的“ISO-8859-1”编码,遇到中文肯定就乱码了。
# 解决方法
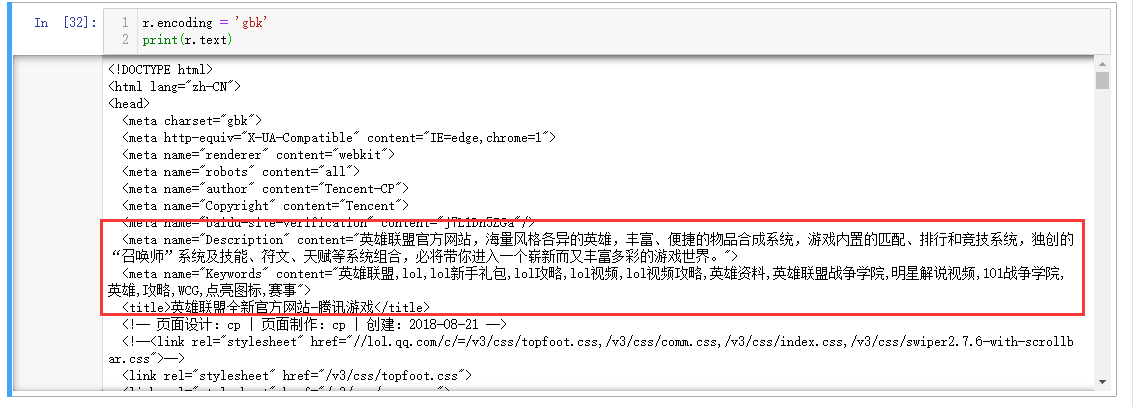
既然是编码方式不对,选择正确的编码就行了。常见的有编码方式有unicode、utf-8、gbk等,怎么才能知道选哪个呢?响应体的html文件head里一般也会说明charset。 如LOL首页:

所以只要把编码方式修改为对应的“gbk”就行了。
response.encoding = 'gbk'
1
然后中文就正常显示了。